Table of Contents
This book is written at a level such that anyone who has taken an introductory computer science course (or has read the book Teach Yourself X in 21 days, where X is C or C++) should be able to understand all the material and work through all of the examples.
However, a data structures course (or a book that explains at least AVL trees, Hash Tables, Graphs, and priority queues), and a software engineering course (or even better, the book Design Patterns) would be very helpful not so much in understanding the following material, but more so in your ability to make the guesses and leaps needed to effectively reverse engineer software on your own.
Reverse engineering as this book will discuss it is simply the act of figuring out what software that you have no source code for does in a particular feature or function to the degree that you can either modify this code, or reproduce it in another independent work.
In the general sense, ground-up reverse engineering is very hard, and requires several engineers and a good deal of support software just to capture the all of the ideas in a system. However, we'll find that by using tools available to us, and keeping a good notebook of what's going on, we should be able to extract the information we need to do what matters: make modifications and hacks to get software that we do not have source code for to do things that it was not originally intended to do.
It comes down to an issue of power and control. Every computer enthusiast (and essentially any enthusiast in general) is a control-freak. We love the details. We love being able to figure things out. We love to be able to wrap our heads around a system and be able to predict its every move, and more, be able to direct its every move. And if you have source code to the software, this is all fine and good. But unfortunately, this is not always the case.
Furthermore, software that you do not have source code to is usually the most interesting kind of software. Sometimes you may be curious as to how a particular security feature works, or if the copy protection is really uncrackable, and sometimes you just want to know how a particular feature is implemented.
This book will teach you a large amount about how your computer works on a low level, and the better an understanding you have of that, the more efficient programs you can write in general.
If you don't know assembly language, at the end of this book you will literally know it inside-out. While most first courses and books on assembly language teach you how to use it as a programming language, you will get to see how to use C as an assembly language generation tool, and how to look at and think about assembly as a C program. This puts you at a tremendous advantage over your peers not only in terms of programming ability, but also in terms of your ability to figure out how the black box works. In short, learning this way will naturally make you a better reverse engineer. Plus, you will have the fine distinction of being able to answer the question "Who taught you assembly language?" with "Why, my C compiler, of course!"
FIXME: Pending... Research here and here (Also be aware of shrink-wrap licenses which forbid reverse engineering if you intend to publish results).
This book is intended to give you an overview of Reverse Engineering under both UNIX and Windows. Most likely you will be initially interested in only one side or the other, but it is always a good idea to understand two different perspectives of the same idea. Even if you are not intending on ever using one of these two platforms now, the day will come when a particular program on one catches your eye, and you say to yourself, "Wouldn't it be neat if that ran on my OS? I wonder how I would go about doing that..." Knowing the general approach can allow you to rapidly adapt to new environments and paradigm shifts (ie you will be less thrown off when say, 64 bit architectures become prevalent, and less helpless when Palladium begins to see widespread usage).
The key insight is to think about how to use these tools and techniques to build as complete a map of your target application/feature as possible. Try not to focus on one tool or even one platform as the end-all-be-all of reverse engineering. Instead, try to focus on the process of information extraction, of fact gathering, and how each tool can give you a piece of the puzzle.
This book is intentionally terse. We have a lot of material to cover, and the learning experience is intended to be hands-on rather than force-fed. We're not going to provide command summaries of every option of every tool. In fact, the most basic tools most likely will not even have output provided for them. The assumption is that the reader is either already familiar with these tools in the course of normal development/system usage, or is willing to play with the tools on their own.
On the contrary, we will not be skimping on the difficult material, such as learning assembly, or code modification techniques that are not as straightforward as simply running tools and looking at output. Hopefully you will still repeat or follow our example in your own projects.
None of the information in this book will be integrated into your thought process, or even retained, if you do not have some reason for reading it. Pick a program for which you want to figure out some small piece of it so that you can do something interesting. Maybe you want to replace a function call in an app to make it do something different, maybe you want to implement a particular feature of a program somewhere else, maybe you want to monitor all data before a program encrypts it and sends it across the network, or maybe you just want to cheat at your favorite multiplayer networked game.
Once you have this goal, define a map of your objectives. Get a multi-subject notebook, and divide it into sections. We suggest a Notes section, a Questions Section, an Active Hypotheses section, and an Experiments section. Date all your entries, and save one section for a general diary, where you jot down a brief timeline of what you've done.
Every fact you pick up about your target application should make you feel a little triumphant. Write it down. Collect everything you can. These will come in handy, especially if the scope of your reversing effort is large.
Remember 8th grade science class? Well guess what, it's relevant to reverse engineering. Essentially reverse engineering is a science in this sense (one could argue much more so than the rest of the slop-shod field of computer science itself). Consider every program you attack to be a system. You are performing educated guesses about that system, and then verifying these educated guesses with a look at the program behavior under a number of observational tools. To refresh your memory, the actual scientific method is an iteration over four steps:
Observe and describe a phenomenon or group of phenomena
This is the first step. You notice something interesting in your application. An interesting behavior, a fluke, or just a sequence of events. Describe this well, trying to establish as many variables, unknowns, requisites and conditions as possible (using these terms in the general scientific sense, not the language syntactic sense - although we will see that these ideas are really parallel).
Formulate a hypothesis to explain these phenomena.
Make an educated guess as to why this behavior occurred. Education is key. Hopefully you understand how software works at this point. And hopefully you have some data structures and pattern experience, or have a really good intuition for guessing how programs work. In any case, try to formulate a guess as to why these behavior are occurring. Some guidelines for this guess is that it should be comparable to the complexity of the feature. If it is something that can be implemented in one self-contained function, well then it should have a few variables that govern its behavior. Make predictions as to what will happen when these variables change.
Sometimes, if you are looking at a large enough feature (or trying to determine a more complicated interaction), you need something more sophisticated than a simple function model. This still fits into this framework. If you have knowledge of finite state machines (which are basically just state transition diagrams) or push down automata (which are state transition diagrams with a stack, and are useful in language/grammar applications), you can go a long way to modeling more pieces of a system using the tools and techniques we introduce in this book. Just be sure to keep it in the back of your mind. If this paragraph scared you, don't worry. It is intended to give a name-drop overview of more formal methods you can use to model systems. The interested reader is encouraged to investigate these topics, but they won't come up in anything but large-scale reverse engineering efforts, usually involving protocols or parsing systems. (FIXME: we should consider devoting a chapter, appendix, or example to such a system)
You may also gain some information by taking a guess at the data structures used, or the design patterns employed. Also, this is usually only relevant to large scale reverse engineering efforts, but again, it fits into the framework and is worth mentioning.
Either try to use your hypothesis to predict new events, or attempt to find events that demonstrate your hypothesis is incorrect or incomplete.
The latter is probably most useful, especially initially when trying to eliminate broad ranges of possibilities. (FIXME: Elaborate on this?)
Use your hypothesis to gain insight into the system, and perhaps even write some code.
If you modify the environment of your program in certain ways, can you predict how this will affect it's behavior? Eventually the time will come to put your hypothesis to the ultimate test: If you code a component the way you think the original works, will your code do the original's job? If your goal is feature implementation details, it is probably a good idea to attempt to recode the feature and use a code modification technique to replace the original feature with yours. If your goal is modification, predict the action of the system under this modification, and verify it.
The most important thing to remember is that this is an iterative process. It converges on a solution through repetition of observation, guessing, testing, and predicting (coding). Initial loops through this process will start with major aspects of the system, and initial hypothesizing and testing should be done by actually using the application. You probably won't bring out the tools until the second or third iteration, and won't dive into the assembly until after that.
If you follow this procedure, you will narrow in on a solution relatively quickly. The most tempting thing is to skimp on the guess stage, and just test. This will get you limited results. You should try to structure your guesses and tests such that they eliminate large classes of possible operation first, and then zero in on the details. Note that nothing says these iterations have to be formal or written down. If your project is small, you can go through two or three iterations of the scientific method right in your head. But you still should be thinking about the system in this manner to be most effective.
If you notice that you have many different hypotheses about how the system works, build tests for them in order. If the feature you are after seems to depend on lots of variables, you should either narrow your focus, or try to develop a hierarchy or tree structure, with the variables that you suspect will effect the largest change at the top, and those that effect less change towards the leaves. Make predictions involving the largest variables first. If you find you have many different possible ways that your feature could work on different levels, again, organize a tree structure with the most likely way at the root, and then use a left branch to indicate that this hypthesis was incorrect, and a right branch to indicate that the general statement was correct. Typically, a correct hypothesis will lead to a whole new hypothesis tree, which you can either include or leave for another diagram, depending on the complexity.
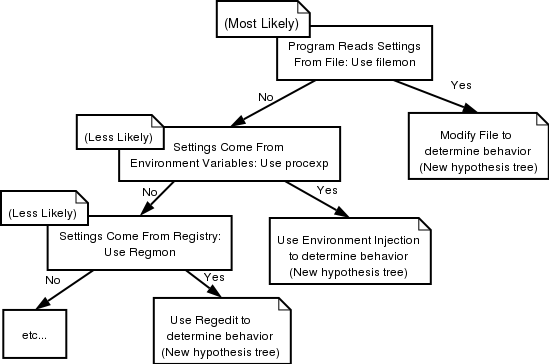
Of course, you don't have to actually draw the tree, but it helps for more complicated scenarios, especially when you're dealing with many features at once. At the very least, this sort of organization should be going on in your head. Furthermore, you may find it useful to have more than two branches at certain points, but only if you can come up with a single test that somehow selects one outcome from several possible ones.
Most of the time for smaller efforts, you will probably only need one or two hypotheses that serve to simply point you in the right direction in the application, however, and you won't need to worry about doing anything complicated. Usually these will be something simple, like "This feature works with the help of such and such system library function(s)." Once you do a linker test to verify this and a trace to see where it calls this function, you're right where you need to be.
![[Tip]](images/tip.png) | NOTE |
|---|---|
If you just haphazardly test without a battle plan, you will be in danger of performing unnecessary/irrelevant tests, or will waste your time looking at a lot of useless assembly code. | |
The rest of the book is structured as a gradual descent from general to specific tools and techniques. We will first introduce tools that are used to gather information about the system/target as a whole. This will give us the information we need to form hypotheses about the next level of detail, namely, how our target is accomplishing various operations. We then can verify this using utilities that allow us a closer look at program behavior. From here, we then reapply the scientific method to hypothesize about the location and function of interesting segments of the program itself, based on which functions are being called from which regions of the program and in what manner. This should give us a hypothesis about the operation of our target in detail, which we then verify by looking at the assembly. (FIXME: Consider adding a "Form Your Hypothesis" section to each chapter).
From this point on, the game is all about how do we want to make use of this information. For this reason, various code modification and interception techniques are presented, including function insertion, RPC interception and buffer overflow techniques.